Start a terminal session from ondemand (or SSH) and download ollama
cd
mkdir ollama
cd ollama
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
tar -xf ollama-linux-amd64.tgz
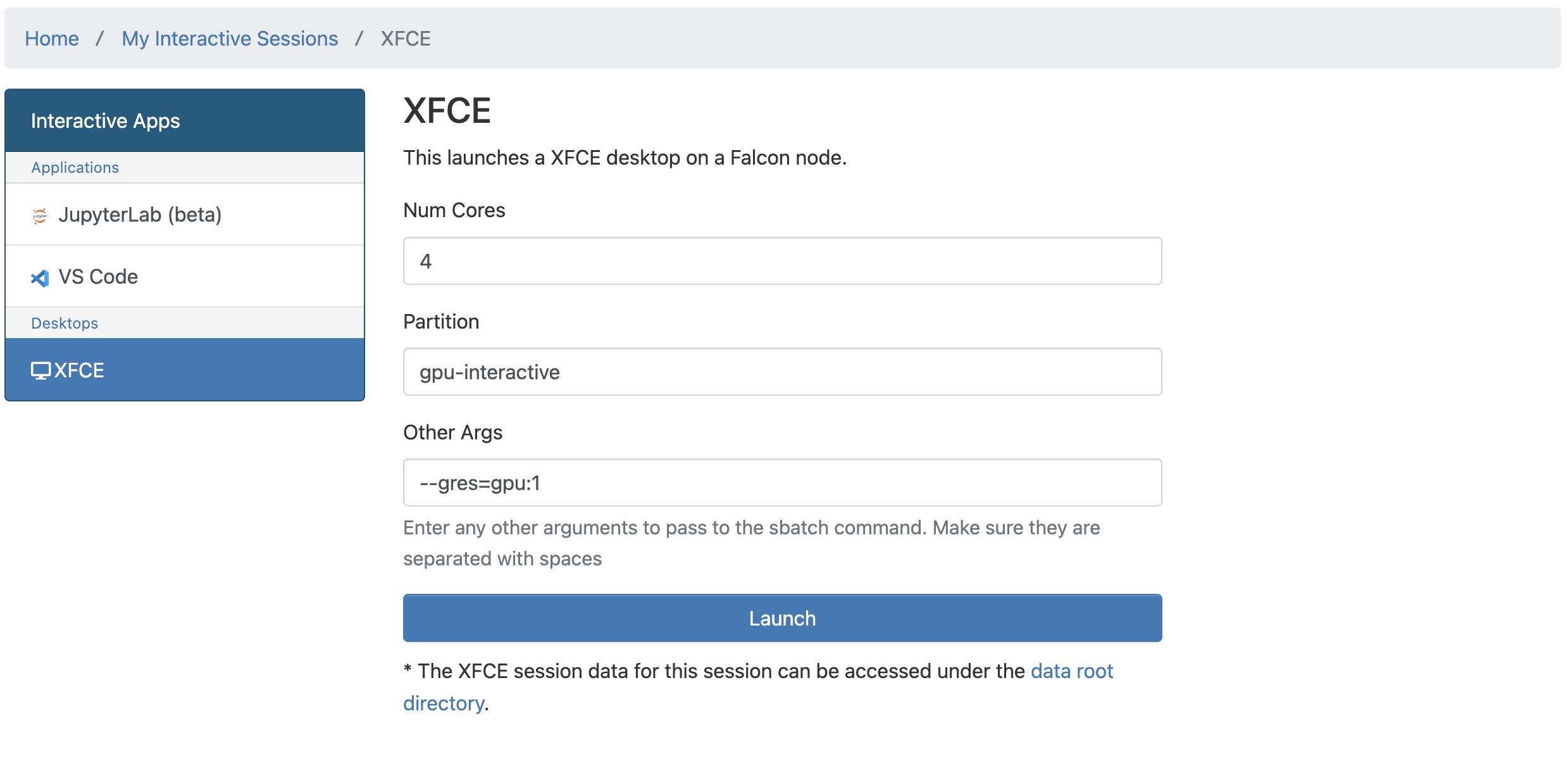
Create an interactive xfce desktop session through ondemand on the gpu-interactive node (or other gpu partition if free)
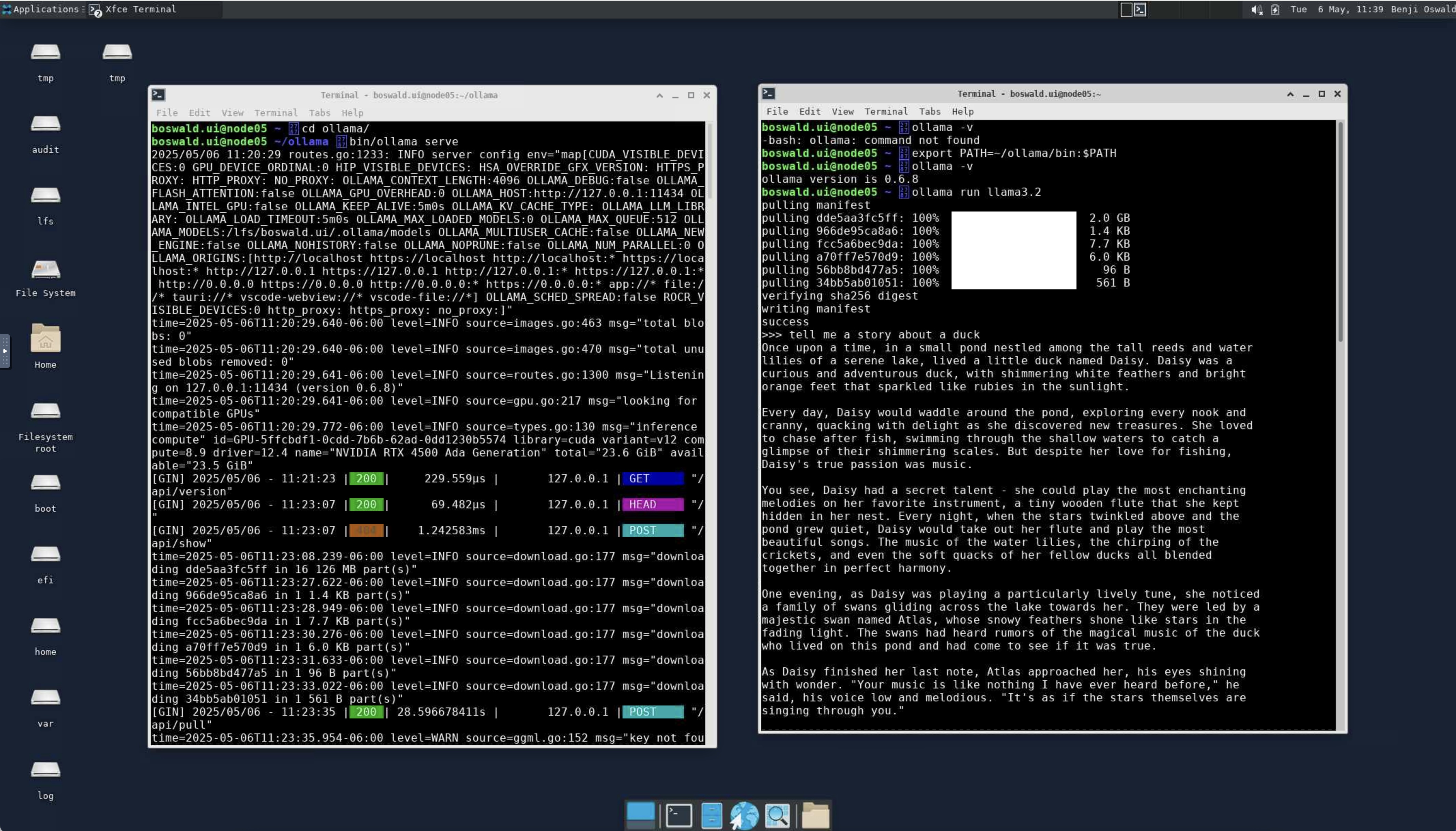
Open a terminal and start ollama
cd ollama
bin/ollama serve
Let it run. Open another terminal window and run commands against the ollama server you have running.
export PATH=~/ollama/bin:$PATH
ollama -v
ollama run llama3.2
Type ctrl-D to stop the interactive ollama session
Create a submit file. Basically you start the ollama serve process in the background - keep track of its PID and then kill it at the end of the script.
#!/bin/bash
#SBATCH -p gpu-volatile
#SBATCH --gres=gpu:1
cd $SLURM_SUBMIT_DIR
export PATH=~/ollama/bin:$PATH
nohup ollama serve > my.log 2>&1 &
echo $! > ollama_pid
ollama run llama3.2 "How long does it take to travel to the moon" > wisdom.txt
kill $(cat ollama_pid)
Create your python file - this one saved as run_ollama.py (don't save it named ollama.py or you'll get weird import errors)
#!/bin/env python3
import ollama
response: ollama.ChatResponse = ollama.chat(model='llama3.2', messages=[
{
'role': 'user',
'content': 'Tell me a story about a falcon who likes to write software?',
},
])
print(response['message']['content'],flush=True)
The submit script loads the alternative set of modules that are on the GPU nodes (which includes a Python module with ollama )
#!/bin/bash
#SBATCH -p gpu-volatile
#SBATCH --gres=gpu:1
hostname
cd $SLURM_SUBMIT_DIR
export PATH=~/ollama/bin:$PATH
nohup ollama serve > ollama.$SLURM_JOB_ID.log 2>&1 &
echo $! > ollama_pid_for$SLURM_JOB_ID
sleep 5
module use /opt/modules/modulefiles
module load python/3.8.11
which python3
python3 run_ollama.py
kill $(cat ollama_pid_for$SLURM_JOB_ID)